티스토리 뷰
스레드 외에도 작업을 비동기로 수행한다.
태스크를 사용하려면 future 헤더가 필요하다.
태스크는 작업 패키기지로 매개변수화 되며, 프로미스(promise)외 퓨처(future) 등 서로 연동되는 두 개의 컴포넌트로 구성된다. 둘 다 데이터 채널을 통해 연결된다.프로미스는 작업 패키지를 실행해 그 결과를 데이타 체널에 보낸다. 그러면 프로미스에 연동된 퓨처가 이 결과를 가져온다. 이 두 교신 지점(Communication endpoint)은 별도의 스레드로 실행될 수 있다. 퓨처는 시간이 약간 흐른 뒤에 결과를 가져올 수 있다는 점에서 특별하다. 따라서 프로미스의 결과 계산은 연동된 퓨처의 결과와 독립적이다.
태스크는 교신 지점 간 데이터 채널과도 같다. 데이터 채널의 한쪽 지점이 프로미스라면 다른 쪽 지점은 퓨처다. 두지점은 동일한 스레드 또는 서로 다른 스레드로 존재할 수 있다 프로미스는 결과를 데이터 채널로 보내고, 퓨처는 이를 기다렸다 가져온다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include <iostream>
#include <future>
#include <thread>
int main()
{
std::cout << std::endl;
int res;
std::thread t([&]{ res = 2000 + 11; });
t.join();
std::wcout << "res ; " << res << std::endl;
auto fut = std::async([] { return 2000 + 11; });
std::cout << "fut.get() : " << fut.get() << std::endl;
std::cout << std::endl;
}
|
cs |
11행 : 스레드가 공유변수인 res 에 계산 결과를 받는다.
14행 : std::async 호출은 발신자(프로미스)와 수신자(퓨처) 사이에 데이터 채널을 만든다. 퓨처는 데이터 채널에 fut.get() 으로 계산 결과를 요청한다. 이 fut.get() 호출은 블로킹이다.
실행결과>
| 기준 | 스레드 | 태스크 |
| 교신 | 공유 변수 | 교신 채널 |
| 스레드 생성 | 필수 | 선택 |
| 동기화 | join() 을 통해 (대기) | get 호출 블록 |
| 자식 스레드의 예외 | 자식 및 생성자 스레드 중단 | 프로미스의 리턴 값 |
| 교신의 종류 | 값 | 값, 알림, 예외 |
스레드에는 thread 헤더, 태스크는 future 헤더 필요
std::async
퓨처를 만들 수 있는 가장 쉬운 방법이다.
비동기 함수 호출과 비슷하다. 인수와 콜러블(callable)을 함께 받기 떄문이다.
std::async 는 가변 템플릿이며, 따라서 임의의 여러 인수를 받을 수 있다. std::async 호출은 퓨처 객체인 fut 을 리턴한다.
시작 정책
비동기 호출이 동일한 스레드(std::launch::deferred) 에서 실행되어야 하는지 아니면 또 다른 스레드(std::launch:async)에서 실행되어야 하는지를 명시벅으로 지정할 수 있다.
기본적으로 std::async 는 자신의 작업 패키지를 곧바로 실행한다. 이 때문에 조급한 계산법으로 불린다.
auto fut = std::async(std::launch::deferred, ...) 호출은 프로미스가 곧바로 실행되지 않는다는 점에서 특별하다. fut.get() 호출은 프로미스를 느긋하게 시작하는데, 이는 다시 말해, 프로미스는 퓨처가 fut.get() 을 통해 결과를 요청할 때만 실행된다는 뜻이다.
퓨처의 조급한 게산법과 느긋한 계산법
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#include <iostream>
#include <future>
#include <thread>
int main()
{
std::cout << std::endl;
auto begin = std::chrono::system_clock::now();
auto asyncLazy = std::async(std::launch::deferred,
[] { return std::chrono::system_clock::now(); });
auto asyncEager = std::async(std::launch::async,
[] { return std::chrono::system_clock::now(); });
std::this_thread::sleep_for(std::chrono::seconds(1));
auto lazyStart = asyncLazy.get() - begin;
auto eagerStart = asyncEager.get() - begin;
auto lazyDuration = std::chrono::duration<double>(lazyStart).count();
auto eagerDuration = std::chrono::duration<double>(eagerStart).count();
std::cout << "asyncLasy evaluted after : " << lazyDuration << " senconds." << std::endl;
std::cout << "asyncEager evaluted after : " << eagerDuration << " senconds." << std::endl;
std::cout << std::endl;
}
|
cs |
15행 : asyncLazy.get() 은 10행의 프로미스 실행을 유발한다. 그 결과는 14행의 짧은 1초 대기 이후에 사용 가능하다.
16행 : asyncEager.get() 은 곧바로 실행된 작업 패키지로부터 결과를 받는다.
실행결과>

std::packaged_task
std::packaged_task pack 은 콜러블(Callable)의 비동기 호출을 위한 래퍼(wrapper) 다.
pack.get_future() 르 ㄹ호출하면 연동돈 퓨처를 받는다. 호출 연산자를 pack 에 호출하면(pack()) std::packaged_task 가 실행되고, 그 결과 볼러블이 실행된다.
std::packaged_task 으 ㅣ관리는 크게 네 단계로 나뉜다.
1. 작업을 래핑한다.
std::packaged_task<int(int, int)> sumTask({}(int a, int b) { return a + b; });
2. 퓨처를 생성한다.
std::future<int> sumResult = sumTask.get_future();
3. 계산을 수행한다.
sumTask(2000, 11);
4. 결과를 조회한다.
sumResult.get();
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
#include <iostream>
#include <future>
#include <thread>
#include <utility>
#include <deque>
class SumUp {
public:
int operator() (int beg, int end) {
long long int sum{ 0 };
for (int i = beg; i < end; i++) sum += i;
return sum;
}
};
int main()
{
std::cout << std::endl;
SumUp sumUp1;
SumUp sumUp2;
SumUp sumUp3;
SumUp sumUp4;
// 태스크 래핑
std::packaged_task<int(int, int)> sumTask1(sumUp1);
std::packaged_task<int(int, int)> sumTask2(sumUp2);
std::packaged_task<int(int, int)> sumTask3(sumUp3);
std::packaged_task<int(int, int)> sumTask4(sumUp4);
// 퓨처 생성
std::future<int> sumResult1 = sumTask1.get_future();
std::future<int> sumResult2 = sumTask2.get_future();
std::future<int> sumResult3 = sumTask3.get_future();
std::future<int> sumResult4 = sumTask4.get_future();
//컨테이너에 태스크 넣기
std::deque<std::packaged_task<int(int, int)>> allTasks;
allTasks.push_back(std::move(sumTask1));
allTasks.push_back(std::move(sumTask2));
allTasks.push_back(std::move(sumTask3));
allTasks.push_back(std::move(sumTask4));
int begin{ 1 };
int increment{ 2500 };
int end = begin + increment;
// 별도의 스레드로 각 계산 수행
while (not allTasks.empty()) {
std::packaged_task<int(int, int)> myTask = std::move(allTasks.front());
allTasks.pop_front();
std::thread sumThread(std::move(myTask), begin, end);
begin = end;
end += increment;
sumThread.detach();
}
// 결과 얻기
auto sum = sumResult1.get() + sumResult2.get() + sumResult3.get() + sumResult4.get();
std::cout << "sum of 0 .. 1000 = " << sum << std::endl;
std::cout << std::endl;
}
|
cs |
25~28행 : std::packaged_task 객체로 작업 패키지를 감싼다. 작업 패키지는 SumUp 클래스의 인스턴스이다. 작업은 호출 연산자로 완료된다. (9~13행) 호출 연산자는 begin에서 end - 1 까지 모든 수를 나타내며 그 합계로 리턴한다. std::packaged_task 는 두개의 int를 사용해 처리하고 하나의 int를 반환하는(int(int, int)) 콜러블들을 관리한다.
31~34행 : std::packaged_task 객체의 도움을 받아 퓨처 객체를 생성해야 한다. packaged_task는 겨신 채널의 프로미스다. 퓨처의 타입은 std::future<int> sumResult1 = sumTask1,get_future() 처럼 명시적으로 정의되지만 컴파일러가
auto sumResult1 = sumTask1,get_future() 로 이를 담당한다.
37~41행 : packaged_task 는 std::deque 로 이동한다.
48~55행 : packaged_task 각 패키지가 실행된다.
52행 : 이를 위해 std::deque 의 헤드를 std::packaged_task 로 옮긴다.
57행 : 백그라운드에서 실행한다.
61행 : 최종 단계에서 모든 퓨처의 값을 요청해서 계산한다.
실행 결과>

std::promise 와 std::future
값이나 예외 또는 다눈 알림을 공유 데이터 채널로 보낼 수 있다. 하나의 프로미스가 std::shared_futue 퓨처 여럿을 담당한다. C++20 에서는 확장퓨처를 제공한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
#include <iostream>
#include <future>
#include <thread>
#include <utility>
void product(std::promise<int>&& intPromise, int a, int b) {
intPromise.set_value(a * b);
}
struct Div {
void operator() (std::promise<int>&& intPromise, int a, int b) const {
intPromise.set_value(a / b);
}
};
int main()
{
std::cout << std::endl;
int a = 20;
int b = 10;
std::cout << std::endl;
// 프로미스 정의
std::promise<int> prodPromise;
std::promise<int> divPromise;
// 퓨처 받기
std::future<int> prodResult = prodPromise.get_future();
std::future<int> divResult = divPromise.get_future();
// 별도의 스레드로 결과 계산
std::thread prodThread(product, std::move(prodPromise), a, b);
Div div;
std::thread divThread(div, std::move(divPromise), a, b);
// 결과 받기
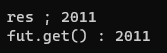
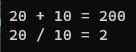
std::cout << "20 + 10 = " << prodResult.get() << std::endl;
std::cout << "20 / 10 = " << divResult.get() << std::endl;
prodThread.join();
divThread.join();
std::cout << std::endl;
}
|
cs |
32행 : prodThread 스레드는 6~8행의 product 함수와 28행의 prodPromise 함수, a와 b 라는 수를 받는다. ProdThread 의 인수를 이해하려면 함수의 서명을 파악해야 한다. prodThread 의 첫번째 인수는 콜러블(Callable) 이어야 하는데, 이느 ㄴ앞서 언급한 product 함수다. product 함수에는 rvalue 레퍼런스(std::promise<int>&& intPromise) 의 프로미스와 두개의 수가 필요한데 이는 prodThread 의 마지막 세 인수다. 32행의 std::move 가 rvalue 레퍼런스를 생성한다.
34행 : 두 수 a와 b 를 나눈다. 이때 Div 클래스의 div 객체가 사용된다. (10~13행) div는 함수 객체의 인스턴스다.
41, 42행 : 퓨처는 prodResult.get() 과 divResult.get() 을 호출해 결과를 가져온다.
실행 결과>
std::promise
값이나 알림, 예외를 설정하는데 사용된다.
결과를 지연 방식으로 제공한다.
| 메서드 | 설명 |
| prom.wap(prom2)와 std::swap(prom, prom2) | 프로미스를 서로 맞바꾼다. |
| prom.get_future() | 퓨차를 반환한다. |
| prom.set_value(val) | 값을 설정한다. |
| prom.set_exception(ex) | 예외를 설정한다. |
| prom.set_value_at_thread_exit(val) | 값을 지정하고, 프로미스 종료 시 사용되도록 준비한다. |
| prom.set_exception_at_thread_exit(val) | 예외를 지정하고, 프로미스 종료 시 사용되도록 준비힌다. |
값이나 예외가 프로미스에 의해 한 번 이상 설정되면 std::future_error 예외가 발생한다.
std::future
프로미스에서 값을 가져온다.
값을 사용할 수 있는지 프로미스에 확인한다.
프로미스의 알림을 기다린다. 이때 상대적 기간(time duration) 이나 절대적 시점(time point) 이 적용된다.
공유 퓨처(std::future)를 생성한다.
| 메서드 | 설명 |
| fut,share() | std::shared_future 를 반환한다. 반환 이후에는 결과를 사용할 수 없다. |
| fut.get() | 값 또는 예외인 결과를 린턴한다. |
| fut.valid() | 결과를 사용할 수 있는지 확인한다. fut.get() 을 호출한 이후에는 false 를 리턴한다. |
| fut.wait() | 결과를 기다린다. |
| fut.wait_for(Time) | 결과를 기다린다. 단, reaTime 이상은 기다리지 않는다. |
| fut.wait_untile(absTime) | 결과를 기다린다. 단, absTime 이상은 기다리지 않는다. |
fut 퓨처가 한 번 이상 결과를 요청하면 std::future_error 예외가 발생한다.
프로미스와 퓨처 사이에는 1:1 관계가 성립한다. 이와 반대로 std::shared_future 는 프로미스외 퓨처 사이에 1:N 관계를 지원한다.
std::shared_future
퓨처는 fut.share() 를 사용해 공유 퓨처를 만든다. 공유 퓨처는 프로미스와 연동되어 결과를 독립적으로 요청할 수 있다. std::shared_future 의 인터페이스는 std::future 와 같다.
std::future 의 기능외에도 연동된 다른 퓨처들과는 독립적으로 프로미스를 쿼리항 수 있다.
두 가지 방법으로 만들 수 있다.
1. std::future 인 fut에 fut.share() 를 호출한다. 호출 이후에는 결과를 더 이상 사용할 수 없다. 따라서 valid==false 가 된다.
2. std::promise 로 부터 std::shared_future를 초기화 한다. (std::shared_future<int> divResult=divPromise.get_future())
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
#include <iostream>
#include <future>
#include <thread>
#include <utility>
std::mutex coutMutex;
struct Div {
void operator() (std::promise<int>&& intPromise, int a, int b) const {
intPromise.set_value(a / b);
}
};
struct Requestor {
void operator() (std::shared_future<int> shaFut) {
// std:;:cout 잠그기
std::lock_guard<std::mutex> coutGuard(coutMutex);
// 스레드 id 받기
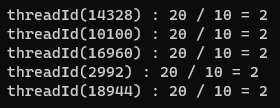
std::cout << "threadId(" << std::this_thread::get_id() << ") : ";
std::cout << "20 / 10 = " << shaFut.get() << std::endl;
}
};
int main()
{
std::cout << std::endl;
// 프로미스 정의
std::promise<int> divPromise;
// 퓨처 받기
std::shared_future<int> divResult = divPromise.get_future();
// 별도의 스레드로 결과 계산
Div div;
std::thread divThread(div, std::move(divPromise), 20, 10);
Requestor req;
std::thread sharedThread1(req, divResult);
std::thread sharedThread2(req, divResult);
std::thread sharedThread3(req, divResult);
std::thread sharedThread4(req, divResult);
std::thread sharedThread5(req, divResult);
divThread.join();
sharedThread1.join();
sharedThread2.join();
sharedThread3.join();
sharedThread4.join();
sharedThread5.join();
std::cout << std::endl;
}
|
cs |
두 작업 패키지, 다시 말해 프로미스와 퓨처의 작업 패키지는 여기서 함수 객체다.
37행 : divPromise는 divThread 스레드로 이동되어 실행된다. 이에 따라 std::shared_future 도 총 다섯개의 스레드로 복사된다. (48~52행) 이 사실은 매우 중요하다 이동될 수 있는 std::future 객체와 반대로 std::shared_future 객체는 복사될 수 있다. 메인 스레드는 48~52행에서 자식 스레드가 일을 마칠때까지 기다렸다가 결과를 표시하게 된다.
실행 결과>
예외 반환하기
executeDivision 함수는 계산 결과 또는 예외를 표시한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
#include <iostream>
#include <future>
#include <thread>
#include <utility>
#include <exception>
#include <string>
struct Div {
void operator() (std::promise<int>&& intPromise, int a, int b){
try {
if (0 == b) {
std::string errMsg = std::string("Illegal division by zero : ") + std::to_string(a) + "/" + std::to_string(b);
throw std::runtime_error(errMsg);
}
intPromise.set_value(a / b);
}
catch (...) {
intPromise.set_exception(std::current_exception());
}
}
};
void execeptionDivision(int nom, int denom) {
std::promise<int> divPromise;
std::future<int> divResult = divPromise.get_future();
Div div;
std::thread divThread(div, std::move(divPromise), nom, denom);
// 결과 또는 예외 받기
try {
std::cout << nom << " / " << denom << " = " << divResult.get() << std::endl;
}
catch (std::runtime_error& e) {
std::cout << e.what() << std::endl;
}
divThread.join();
}
void main()
{
std::cout << std::endl;
execeptionDivision(20, 0);
execeptionDivision(20, 10);
std::cout << std::endl;
}
|
cs |
프로미스는 분모가 0 이라는 문제를 처리한다. 분모가 0 이면 18행의 intPromise.set_exception(std::current_exception()) 처럼 예외를 반환 값으로 설정한다. 퓨처는 30~35행의 try~catch 블록에서 이 예외를 처리한다.
실행 결과>

가능하다면 조건 변수 대신 태스크를 사용하는 것이 안전해서 좋다
알림 반환하기
스레드를 동기화하는데 프로미스와 퓨처를 사용한다면 조건 변수를 사용할 때ㄹ와 공통점이 많아진다. 대개는 프로미스와 퓨처가 더 나은 선택이다.
| 기준 | 조건 변수 | 태스크 |
| 다수 동기화 | 에 | 아니오 |
| 임계 구역 | 예 | 아니오 |
| 수신자와 오류 처리 | 아니오 | 예 |
| 가짜 깨우기 | 예 | 아니오 |
| 사라진 깨우기 | 예 | 아니오 |
프로미스에 비해 조건 뱐숙 우위를 점하는것은 스레드 동기화를 여러번 할 수 있다는 점이다. 이와 반대로 프로미스는 알림을 한 번만 보낼 수 있으므로 조건 변수 같은 기능을 발휘하기 위해서는 더 많은 프로미스와 퓨처를 사용해야 한다. 만일 한 번 동기화 하는데 조건 변수르 ㄹ사용한다면 오히려 사용법만 훨씬 더 복잡해진다. 프로메미스외 퓨처는 공유 변수가 필요하지 않으며, 그에 따라 잠김도 필요하지 않다. 그리고 가자 깨우기나 사라진 꺠우기에 취약하지도 않다. 더구나 태스크는 예외를 처리할 수 있다. 조건 변수보다 태스크를 선호할 이유는 부지기수다.
조건 변수(condition varibles) 를 사용하는것이 얼마나 어려운지 기억하고 있을지 모르겠다 여기서는 두 스레드를 동기화하기 위한 핵심 부문만 제시하고자 한다.
setDataReady 함수는 동기화의 알림 부분을 수행하며, waitingForWork 함수는 대기 부분을 수행한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#include <iostream>
#include <future>
#include <utility>
void doTheWork() {
std::cout << "Processing share data." << std::endl;
}
void waitingForWork(std::future<void>&& fut) {
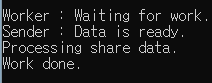
std::cout << "Worker : Waiting for work." << std::endl;
fut.wait();
doTheWork();
std::cout << "Work done." << std::endl;
}
void setDataReady(std::promise<void>&& prom) {
std::cout << "Sender : Data is ready." << std::endl;
prom.set_value();
}
void main()
{
std::cout << std::endl;
std::promise<void> sendReady;
auto fut = sendReady.get_future();
std::thread t1(waitingForWork, std::move(fut));
std::thread t2(setDataReady, std::move(sendReady));
t1.join();
t2.join();
std::cout << std::endl;
}
|
cs |
22행 : sendReady 덕분에 fut 퓨처를 받는다. 프로미스는 유일하게 알림을 보낼 수 있는 std::promise<void> sendReady (21행) 반환값을 사용해서 교신한다. 두 교신점은 스레드 t1 과 스레드 t2 (23, 24행) 로 이동된다. 퓨처는 fut.wait() 호출을 사용해(10행) 프로미스의 알림을 기다린다. (16행)
프로그램의 구조와 출력 결과는 조건 변수(condition variable) 절의 해당 프로그램과 일치한다.
실행 결과>